
Tracking the Original Source for Combined Datasets
Best practices for tracking the original source for datasets that are combined before being added to Tamr Cloud.
Depending on your use case, you may want to combine records from multiple source datasets into a single database table or file before adding the source to Tamr Cloud.
For example, you might store customer data in three different Snowflake tables: North_America_Customers, South America_Customers, and APAC_Customers. You might choose to combine these records into a single Customers table in your Snowflake staging zone, and add that single table as a source dataset in Tamr Cloud.
In the examples below, the combined source dataset added to Tamr Cloud is named combined_source_dataset.csv, and it contains records from the acquired_SFDC.csv and SFDC_connection.csv datasets.
If you need to track the original source for these combined records, you can make slight adjustments to the combined source dataset and to the Tamr Cloud data product flow. Making these adjustments will allow you to:
-
See the original source dataset for each record on the Source Records page.
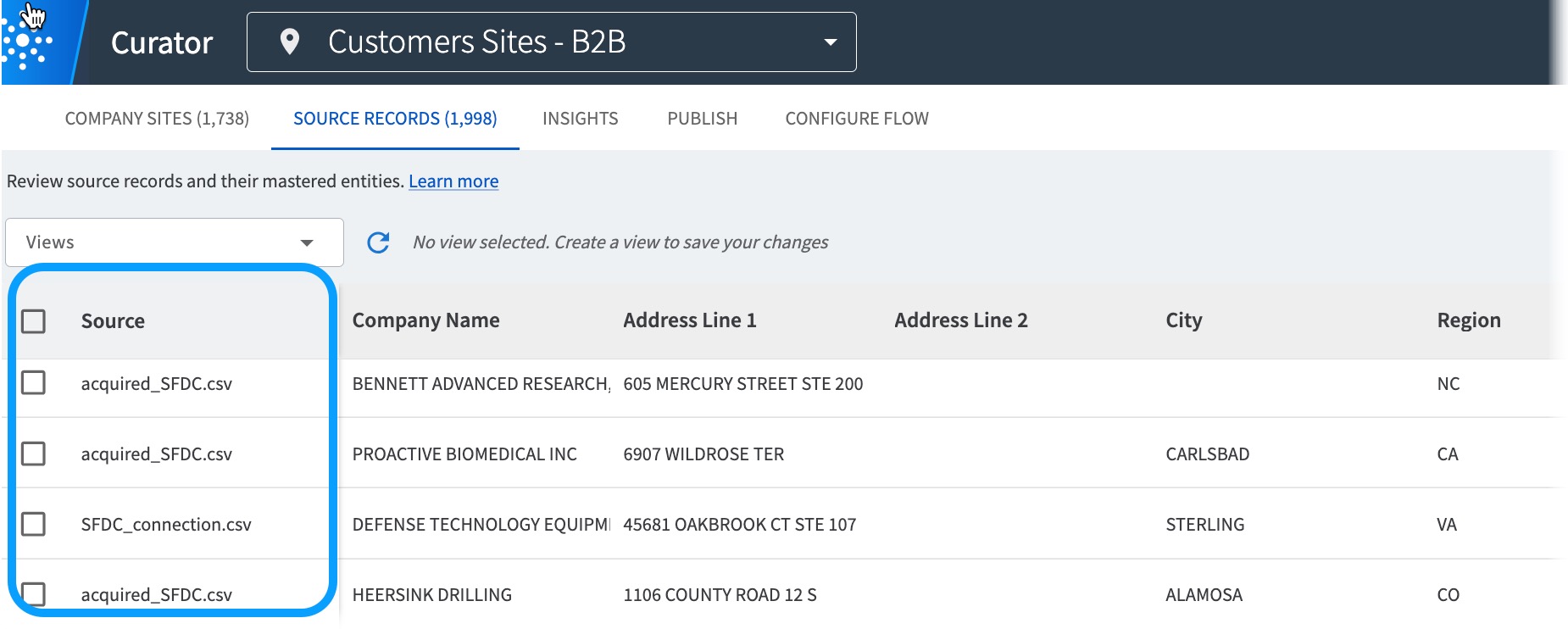
-
In the Attribute Overrides page, see the original source datasets associated with alternate values.
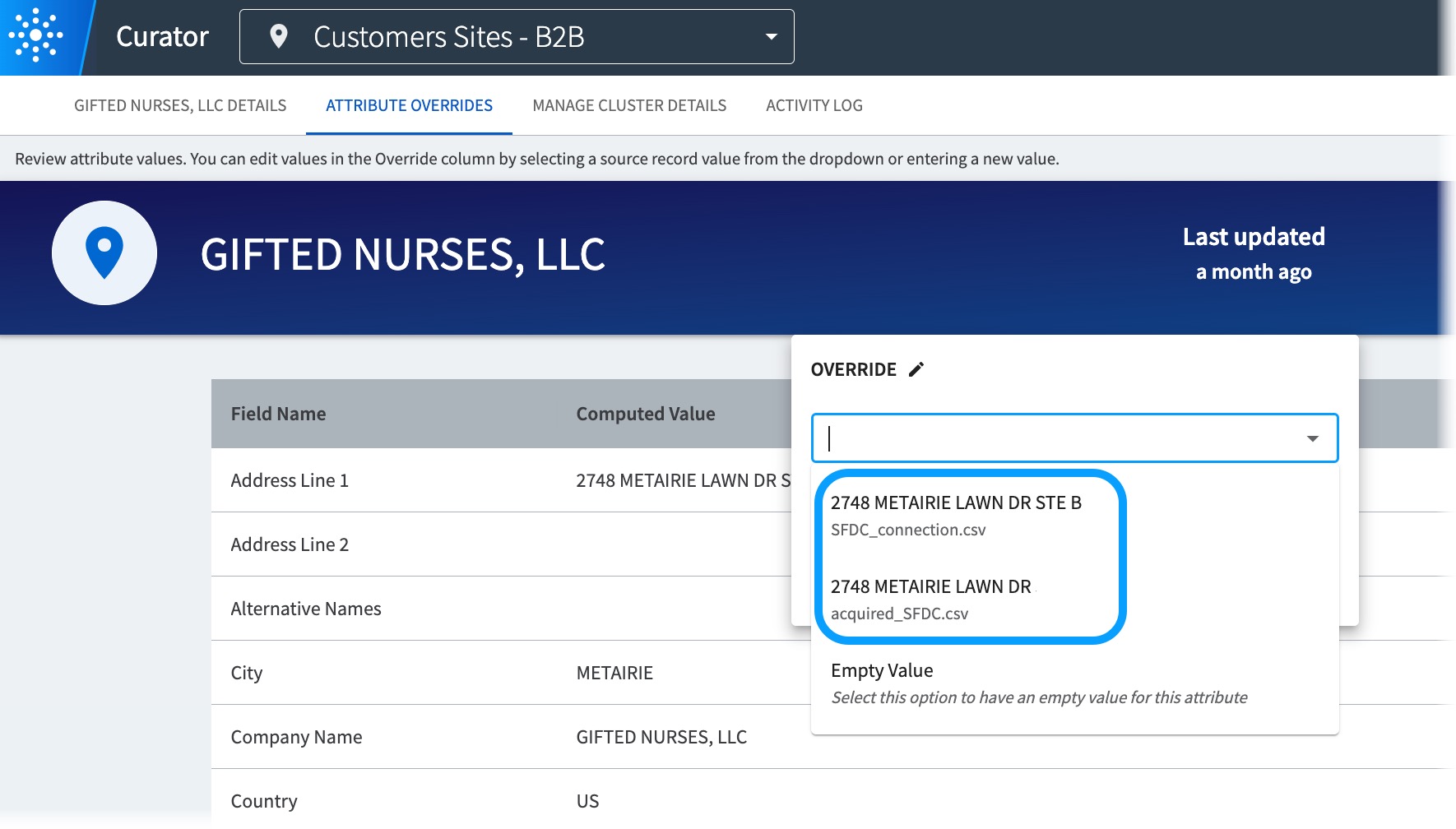
-
View Source Details insights for key metrics for each of the original source datasets.
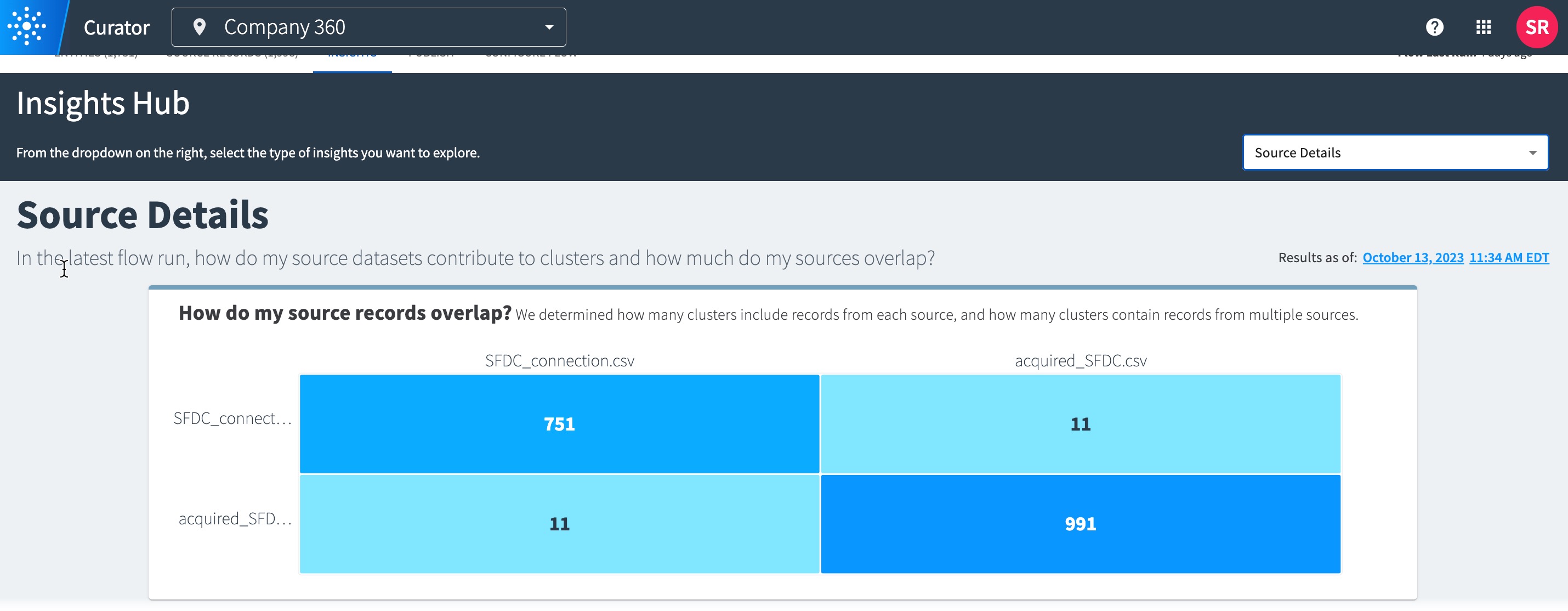
To maintain the original source dataset names:
-
Before adding the source to Tamr cloud, add and populate a column in the combined in the dataset for the original source dataset value (
<original_source_dataset>). -
In the Schema Mapping step in the flow, create a new unified attribute (
<Original_Source_Dataset>) to store the values from this column, and map the<source_dataset>column to it. -
In the Create_tamr_record_id step in the flow, add a transformation to use the value of the
<Original_Source_Dataset>attribute as the pre-defined source_dataset_name source record attribute. (Tamr creates thesource_dataset_nameattribute to track the source for each record.)SELECT *,
<Original_Source_Dataset> as source_dataset_name;
Updated 4 months ago